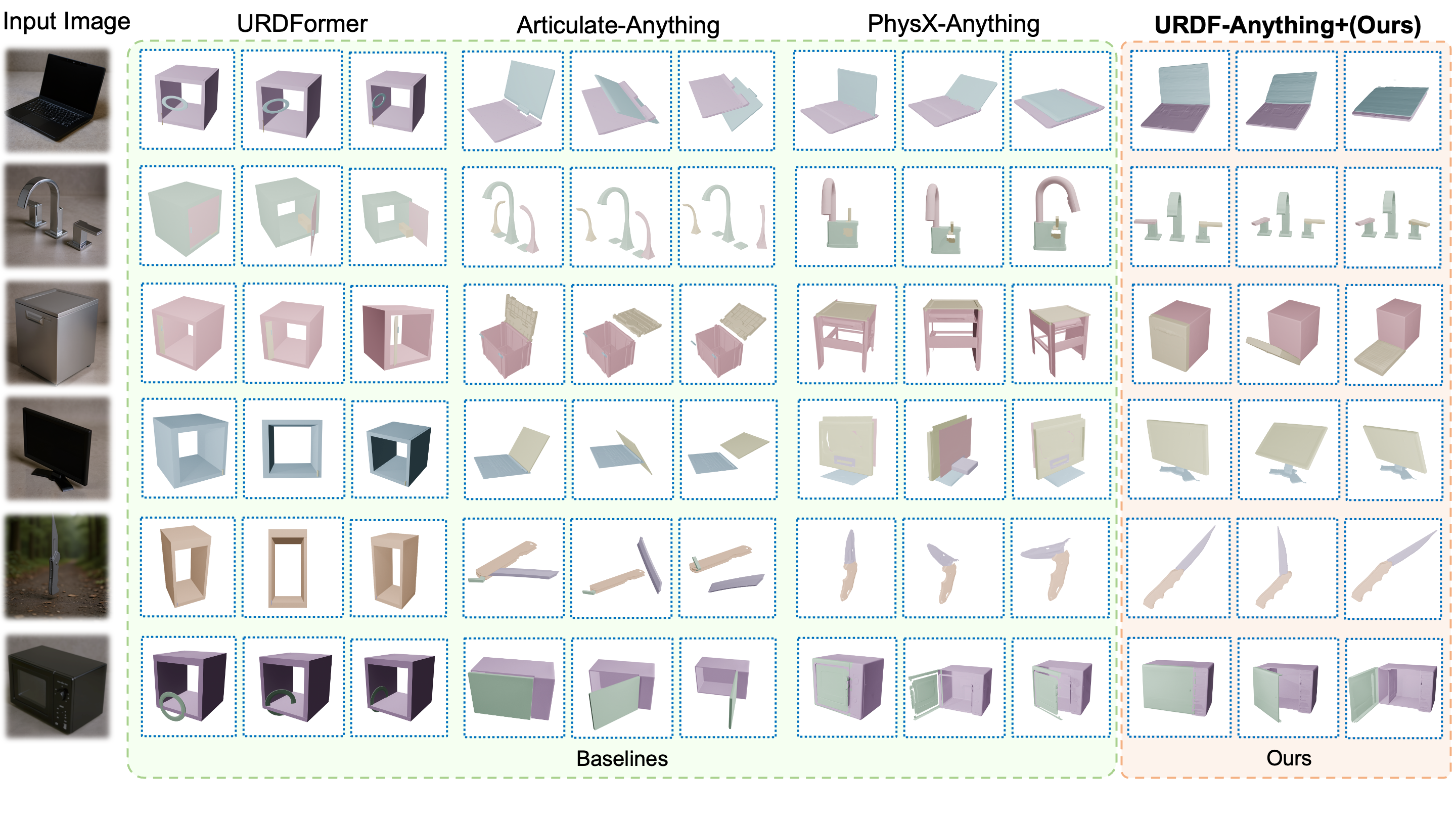
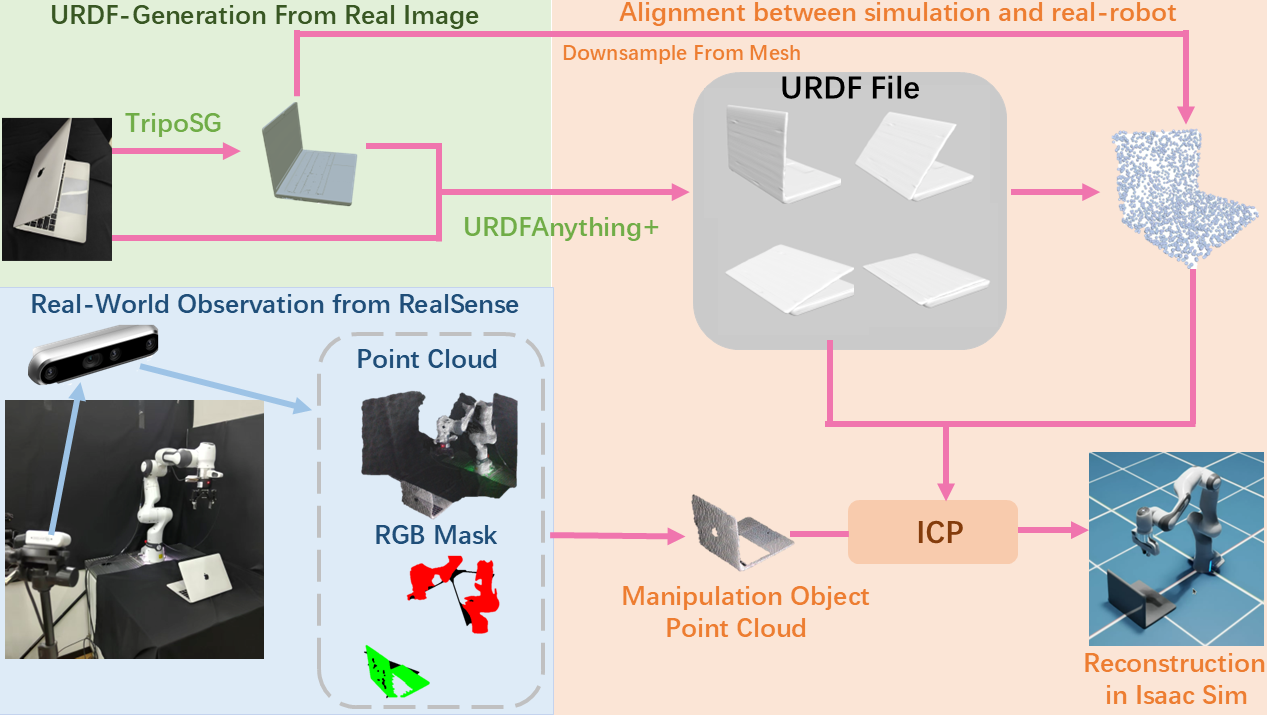
Articulated objects are fundamental for robotics, simulation of physics, and interactive virtual environments. However, reconstructing them from visual input remains challenging, as it requires jointly inferring both part geometry and kinematic structure.
We present URDF-Anything+, an end-to-end autoregressive framework that directly generates executable articulated object models from visual observations.
Given image and object-level 3D cues, our method sequentially produces part geometries and their associated joint parameters, resulting in complete URDF models without reliance on multi-stage pipelines.
The generation proceeds until the model determines that all parts have been produced, automatically inferring complete geometry and kinematics.
Building on this capability, we enable a new Real-Follow-Sim paradigm, where high-fidelity digital twins constructed from visual observations allow policies trained and tested purely in simulation to transfer to real robots without online adaptation.
Experiments on large-scale articulated object benchmarks and real-world robotic tasks demonstrate that URDF-Anything+ outperforms prior methods in geometric reconstruction quality, joint parameter accuracy, and physical executability.